Engenharia de Dados
Pipeline de ETL completa com dados da ANS usando Databricks, AWS e Spark
10/07/2024
13 minutos
Objetivo
O objetivo do projeto é construir uma pipeline de dados completa, que deve incluir ingestão/coleta, modelagem, transformação e carga, utilizando o ambiente do Databricks com AWS. Além disso, ao final, vamos analisar os dados, a fim de responder perguntas previamente definidas.
Vamos trabalhar com os dados da Agência Nacional de Saúde Suplementar (ANS) na plataforma do Databricks. A agência disponibiliza grandes volumes de dados sobre operadoras de planos de saúde e beneficiários, em formato aberto.
Alguns conjuntos de dados possuem dezenas e centenas de gigabytes, o que representa um desafio interessante para colocar em prática alguns conhecimentos de processamento distribuído, modelagem de dados em Data Lakehouses, e arquitetura Apache Spark.
Em relação à plataforma utilizada, utilizei o free-trial do Databricks na versão Premium. Além disso, optei pela AWS como ambiente cloud para o workspace do Databricks, por já ter familiaridade com a plataforma, mas também pode ser usada a Azure e GCP.
A opção por não utilizar o Databricks Community (versão gratuita) foi feita visando ter mais contato com um ambiente "real", mais próximo do utilizado pelas empresas, e para ter acesso a algumas funcionalidades fundamentais, como a ferramenta de orquestração de pipelines (Databricks Workflows) e a conexão com repositórios no GitHub.
Devido ao uso da versão Premium, a execução do trabalho incorreu em alguns custos, que serão apresentados e discutidos adiante. Também foram utilizadas instâncias de servidor EC2, além dos clusters criados pelo Databricks, para seção de analytics do trabalho.
Perguntas
As perguntas/problemas que desejo responder através das análises são:
-
Qual é o atual índice de sinistralidade no setor de seguros de saúde?
-
Qual é a seguradora mais eficiente do ponto de vista de custo por beneficiário?
-
Qual é o market share em número de beneficiários no segmento médico-hospitalar?
-
Quantas empresas de plano de saúde existem no Brasil?
-
Quantos beneficiários existem no Brasil? Qual é a taxa de cobertura?
-
Existem mais planos individuais ou coletivos?
Coleta
A ANS disponibiliza todos os seus dados abertos através de um servidor FTP, que pode ser acessado através do link.
Os dados têm boa qualidade, no geral, e são bem organizados, sendo a grande maioria acompanhada de um arquivo de metadados ou catálogo. Alguns catálogos informam, inclusive, que algumas colunas são chaves estrangeiras de tabelas em outros conjuntos de dados, o que é muito útil.
Alguns dos dados utilizados, como apresentado, têm grandes volumes, como o cadastro de beneficiários ativos, divulgado mensalmente, que possui cerca de 10 GB em arquivos .csv, totalizando cerca de 14,5 milhões de registros e 22 atributos, para cada mês.
Os dados são disponibilizados em arquivos compactados .zip, por isso, o código para coleta de dados envolve a extração dos arquivos, leitura em memória, e persistência em um volume no Databricks (ou storage no S3), que serviu como landing/camada raw.
Esse procedimento de persistência dos dados em uma camada raw, fora do ambiente do Delta Lake, é uma forma de evitar problemas comuns com grandes volumes de dados e clusters Spark, como spill.
Após salvar os arquivos no storage, o código faz a leitura usando pyspark, e a ingestão na camada bronze, em formato Delta. O processo de ingestão dos dados e criação da camada bronze foi feito através de classes de ingestão, como bronze_beneficiarios.py.
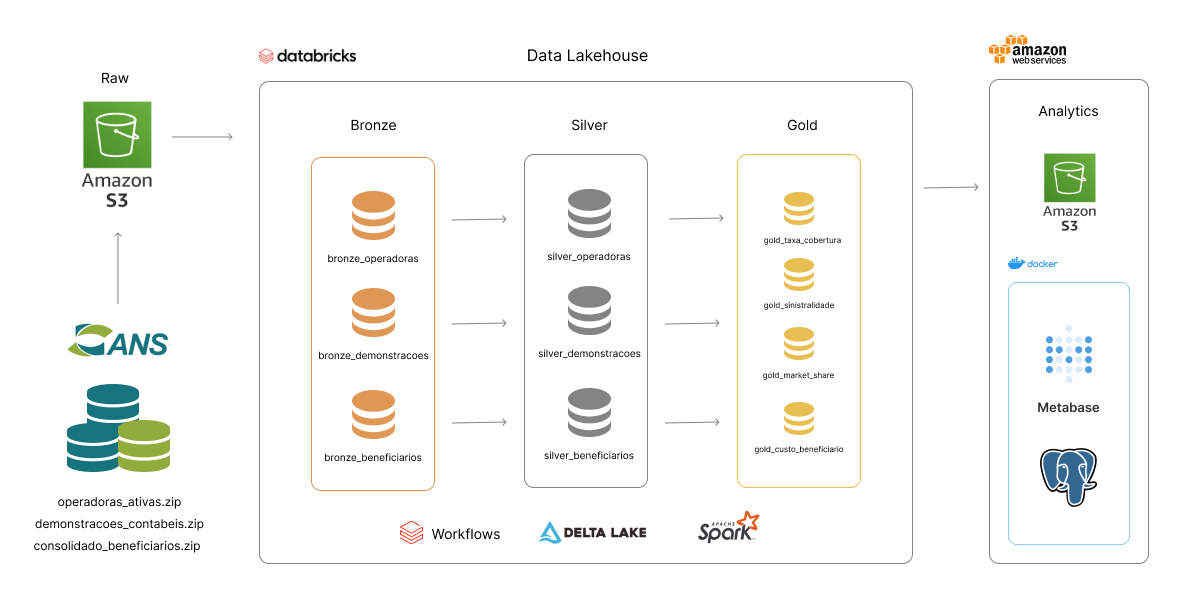
Modelagem
Escolhi para o projeto criar um data lake, que consiste em salvar os dados estruturados e não-estruturados, sem um schema definido, que serão trabalhados em outras etapas ou consumidos por aplicações.
O "problema" dos data lakes tradicionais é que os dados são salvos da mesma forma que foram capturados, o que significa, geralmente, que esses dados têm baixa qualidade e não passaram por constraints e camadas de processamento.
Uma solução para esse problema, muito adotada por profissionais que utilizam a plataforma do Databricks pela fácil integração, é o framework open-source Delta Lake e a arquitura de data lakehouses.
Esse framework consiste em uma camada de abstração construída em cima do seu data lake tradicional (Amazon S3, por exemplo), que incentiva a criação de fluxos de dados em camadas, em que cada camada o dado é tratado e é trabalhado em níveis incrementais de qualidade.
Essas camadas são:
- Bronze: tabelas em formato bruto, com máximo de fidelidade ao dado original coletado;
- Silver: tabelas com estrutura e schema definidos, realizada limpeza e enriquecimento dos dados;
- Gold: tabelas agregadas com métrias de interesse de acordo com a regra de negócio.
Linhagem dos Dados e Metastore
Ao salvar as tabelas em formato delta e utilizando o Unity Catalog, é possível usufruir de funcionalidades integradas do metastore do Databricks, como controle de acesso, métricas de uso, visualização de schema e linhagem dos dados.
Para ilustrar essa funcionalidade, podemos observar o diagrama de linhagem dos dados da tabela gold.ans.custo_beneficiario, que utiliza 4 (quatro) tabelas como origem:
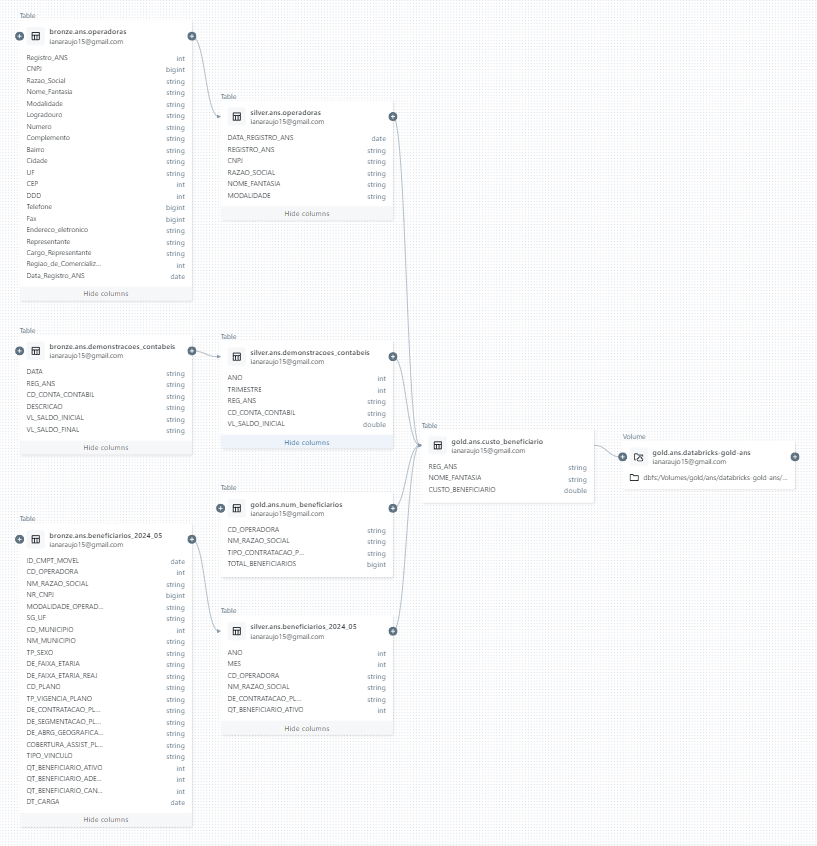
No schema das tabelas da camada bronze (à esquerda da imagem) há maior dimensionalidade, além de dados com tipos inapropriados, nomes de colunas de diferentes formatos, entre outras características de dados em menor qualidade.
Um exemplo é na coluna "CNPJ" da tabela bronze.ans.operadoras, que ao ler os dados usando Spark, foi inferido um tipo bigint, enquanto o correto seria string. Essa transformação é feita na camada silver e na tabela silver.ans.operadoras já podemos ver a mudança feita.
O código utilizado para transformação desses dados na camada silver pode ser encontrado em /src/silver/silver_operadoras.py.
df = spark.sql(f'SELECT * FROM bronze.{schema}.{table}')
upper_cols = [col.upper() for col in df.columns]
df = df.toDF(*upper_cols)
final = df \
.withColumn('REGISTRO_ANS', df['REGISTRO_ANS'].cast('string')) \
.withColumn('RAZAO_SOCIAL', F.regexp_replace(F.col('RAZAO_SOCIAL'), r'[./]', '')) \
.withColumn('RAZAO_SOCIAL', F.regexp_replace(F.col('RAZAO_SOCIAL'), r'\b(LTDA|SA|EIRELI|ME|EPP)\b', '')) \
.withColumn('RAZAO_SOCIAL', F.regexp_replace(F.col('RAZAO_SOCIAL'), r' - $', '')) \
.withColumn('CNPJ', df['CNPJ'].cast('string')) \
.select(
'DATA_REGISTRO_ANS',
'REGISTRO_ANS',
'CNPJ',
'RAZAO_SOCIAL',
'NOME_FANTASIA',
'MODALIDADE'
)
final = final.withColumn('NOME_FANTASIA', F.when(
F.col('NOME_FANTASIA').isNull(), F.col('RAZAO_SOCIAL')).otherwise(F.col('NOME_FANTASIA')
))
final.write.mode('overwrite').format('delta').saveAsTable(f'silver.{schema}.{table}')
Destaque para o código que transforma os dados da coluna "CNPJ" em string.
.withColumn('CNPJ', df['CNPJ'].cast('string'))
Além dessa transformação, na camada silver, é feito um tratamento da RAZAO_SOCIAL, removendo termos comuns (LTDA, SA, EIRELI, etc). Quando NOME_FANTASIA é NULL, o código substitui o campo nulo pelo valor da RAZAO_SOCIAL.
Exemplo: Custo por Beneficiário
Dessa forma, conforme as tabelas avançam no fluxo, é definido um schema, até chegar na tabela gold que será consumida pelo ambiente de analytics, para geração de insights e produtos de dados, como dashboards.
A tabela gold.ans.custo_beneficiario, que calcula um indicador setorial relacionado à eficiência da operadora, é um bom exemplo, pois utiliza todas as 3 (três) fontes primárias para ser construída.
Na camada gold, na maioria dos casos, utilizei a linguagem SQL para criar as tabelas:
CREATE OR REPLACE TABLE gold.ans.custo_beneficiario
USING DELTA AS (
WITH despesas AS (
SELECT ANO, REG_ANS, AVG(VL_SALDO_INICIAL) AS TOTAL_DESPESAS
FROM silver.ans.demonstracoes_contabeis
WHERE ANO = 2023 AND CD_CONTA_CONTABIL = '41'
GROUP BY ANO, REG_ANS
),
beneficiarios AS (
SELECT CD_OPERADORA, SUM(TOTAL_BENEFICIARIOS) AS NUM_BENEFICIARIOS
FROM gold.ans.num_beneficiarios
GROUP BY CD_OPERADORA
),
operadoras AS (
SELECT * FROM silver.ans.operadoras
WHERE LOWER(MODALIDADE) NOT LIKE '%odonto%'
)
SELECT d.REG_ANS, o.NOME_FANTASIA, ROUND(d.TOTAL_DESPESAS / b.NUM_BENEFICIARIOS, 2) AS CUSTO_BENEFICIARIO
FROM despesas AS d
LEFT JOIN beneficiarios AS b ON d.REG_ANS = b.CD_OPERADORA
LEFT JOIN operadoras AS o ON d.REG_ANS = o.REGISTRO_ANS
WHERE b.NUM_BENEFICIARIOS > 0 AND d.TOTAL_DESPESAS > 0
);
Ao final do fluxo de transformações, a tabela na camada gold possui apenas 3 (três) domínios, seguindo o catálogo abaixo:
| Variável | Tipo | Descrição |
|---|---|---|
| REG_ANS | string | Código ANS de identificação da operadora |
| NOME_FANTASIA | string | Nome fantasia da operadora |
| CUSTO_BENEFICIARIO | double | Custo por beneficiário em reais (R$) por trimestre |
Essa tabela final está pronta para ser consumida por dashboards ou por stakeholders dentro da organização, sendo possível rankear as empresas da mais eficiente para a menos eficiente, assim como fazer joins com outras tabelas, como gold.ans.market_share, e comparar a eficiência entre as líderes do mercado.
Carga
Todas as etapas da pipeline de ETL (extração, transformação e carga) foram feitas de forma automatizada e utilizando Python (pyspark), SQL e o Databricks Workflows (orquestrador).
Se considerarmos a etapa de ingestão na camada raw, o processo segue a lógica de ELT (extração, carga e transformção), de modo que os dados são coletados e carregados como arquivos no formato original (.csv), em uma landing zone, e só depois são transformados em tabelas delta.
A escolha por adotar esse processo foi devido ao grande volume dos conjuntos de dados de demonstrações_contábeis e beneficiários, além da eficiência gerada por essa abordagem, resultando em operações mais rápidas e sobrecarga reduzida nos clusters.
Todos os arquivos utilizados para construção da pipeline de ETL (ou ELT), separados em camadas bronze, silver e gold, podem ser consultados neste repositório na pasta /src.
Além dos códigos utilizados para pipeline dos dados da ANS, no diretório /src também pode ser encontrado o arquivo export.py.
Por ter usado o Databricks Premium, após o período de teste de 14 dias, não farei mais uso do workspace e ambiente de Delta Lake construído, em razão da incidência de custos adicionais.
Para manter os dados gerados, mesmo após encerrar o workspace no ambiente do Databricks, criei um shared volume - que liga o Databricks a um storage externo no ambiente da AWS, no meu caso o S3 - e um código em Python que carrega todas as tabelas da camada gold nesse volume em formato parquet.
Dessa forma, eu garanto o acesso ao dados do Databricks no meu ambiente da AWS, mesmo após encerrar meu período de utlização da plataforma.
O código utilizado para realizar essa etapa final foi:
bucket = 'databricks-gold-ans'
database = 'gold.ans'
tables = spark.sql(f'show tables in {database}')
def export_parquet(bucket: str, database: str, table: DataFrame) -> None:
df = spark.read.table(f'{database}.{table.tableName}')
save_path = f'/Volumes/gold/ans/{bucket}/{table.tableName}'
df.repartition(1) \
.write.mode('overwrite') \
.format('parquet') \
.option("header","true") \
.option("inferSchema", "true") \
.save(save_path)
parquet_file = [file.name for file in dbutils.fs.ls(save_path) if file.name.startswith('part-')]
dbutils.fs.mv(save_path + "/" + parquet_file[0], f"{save_path}.parquet")
for file in dbutils.fs.ls(save_path):
dbutils.fs.rm(file.path)
dbutils.fs.rm(save_path)
print(f"Saved '{table.tableName}.parquet' to {bucket}!")
for table in tables.collect():
export_parquet(bucket, database, table)
print("All data exported!")
Databricks Workflows
Todos os processos descritos acima, incluindo a coleta dos dados, transformações, carga e exportação dos dados finais para AWS, foram automatizados utilizando a funcionalidade do Databricks Workflows.
O Databricks Workflows é um serviço integrado na plataforma para fazer a orquestração de pipelines, de forma similar a outras soluções no mercado, como Airflow, Dagster, Prefect, etc.
Assim como os demais, é possível agendar execuções, triggers, monitorar falhas e logs, e definir de forma visual a ordem de execução das tarefas.
A grande vantagem do Databricks Workflows, frente aos outros serviços, é a integração com a plataforma. As tarefas de um workflow podem utilizar clusters dedicados - chamados de job clusters, que são ligado e depois terminados apenas para execução da pipeline - e podem ser definidas a partir dos próprios notebooks do Databricks.
Dessa forma, é possível utilizar diversas liguagens, como Python, SQL, Scala e R, na mesma pipeline.
Ao final da configuração de um workflow, é também possível gerar um arquivo .json, que foi salvo em workflows/pipeline.json, e permite versionar os jobs, além de definir programaticamente uma visualização da sua pipeline:
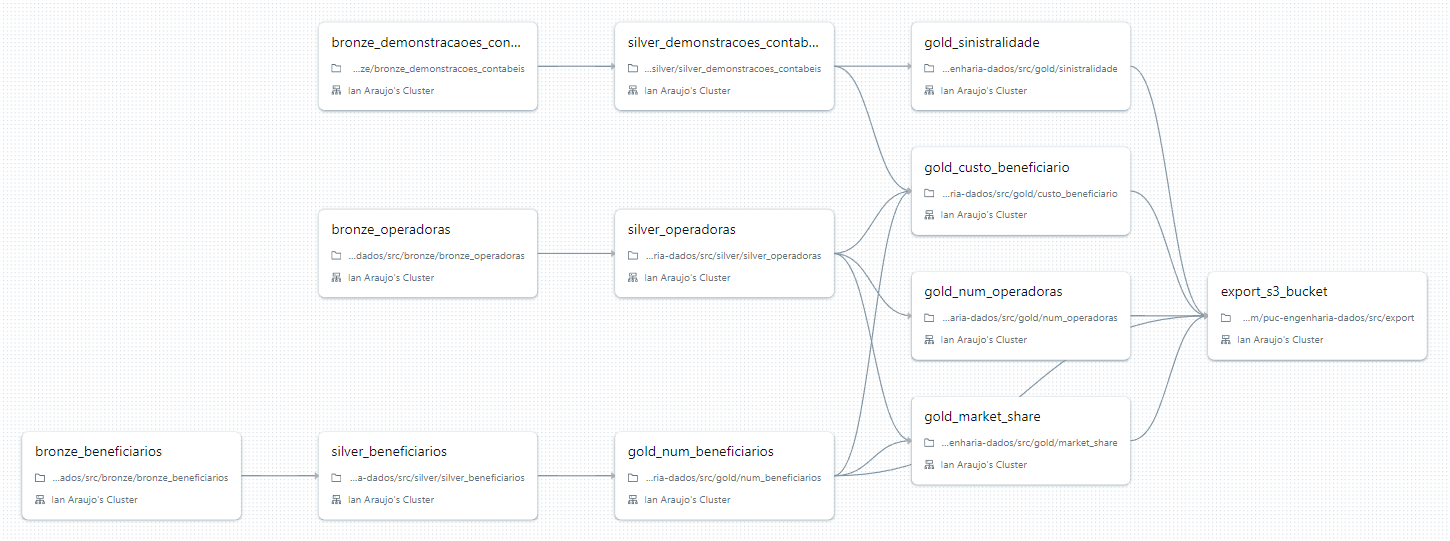
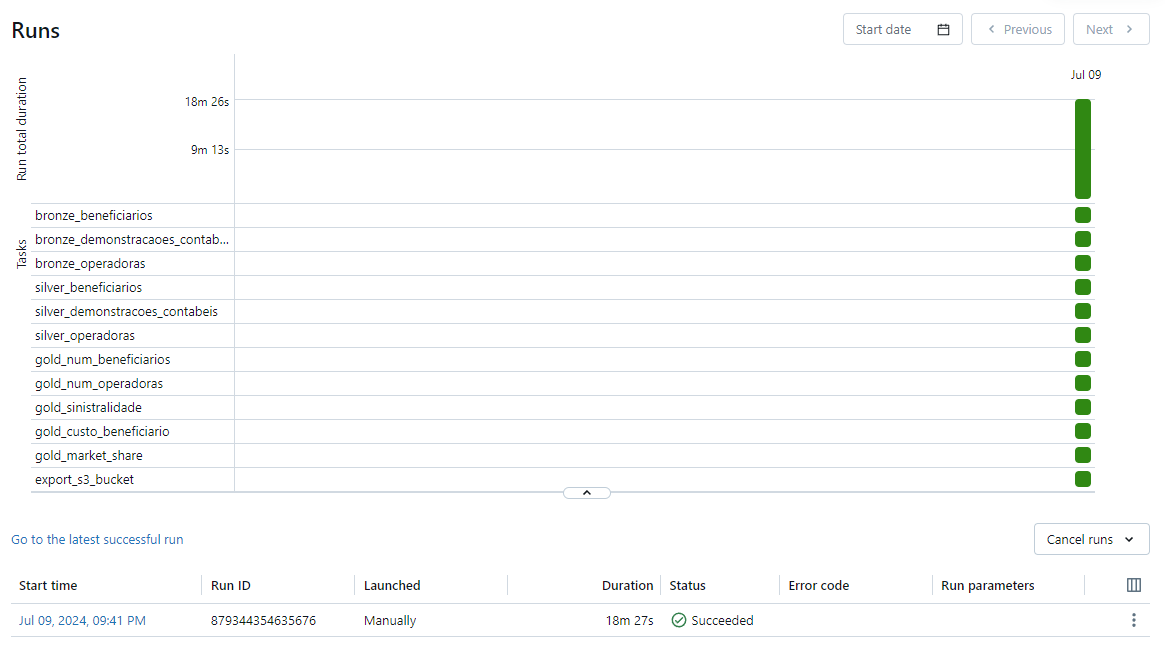
Podemos observar que a pipeline teve duração total de 18 minutos e 27 segundos, e todas as tarefas foram concluídas com sucesso. No contexto de big data e janelas de produção batch não é um tempo muito grande, embora exista margem para tornar o código mais eficiente ou utilizar clusters mais potentes, o que aceleraria a execução da pipeline.
Análise do Dados
A etapa de análise foi desenvolvida utilizando SQL em um ambiente de analytics criados fora no Databricks, na AWS, utilizando o Metabase, hospedado usando Docker. As tabelas da camada gold foram carregadas em um bancos de dados PostgreSQL, sendo possível realizar consultas, responder as perguntas definidas no início do trabalho e gerar visualizações.
As perguntas poderiam ter sido respondidas no ambiente do Databricks, no entanto, escolhi criar um ambiente separado de analytics usando o Metabase, um serviço open-source de BI e dashboards.
No Metabase é possível definir "Questions", que podem ser consultas SQL. Após criar as questions, organizadas em coleções lógicas específicas, elas podem ser usadas para criar dashboards.
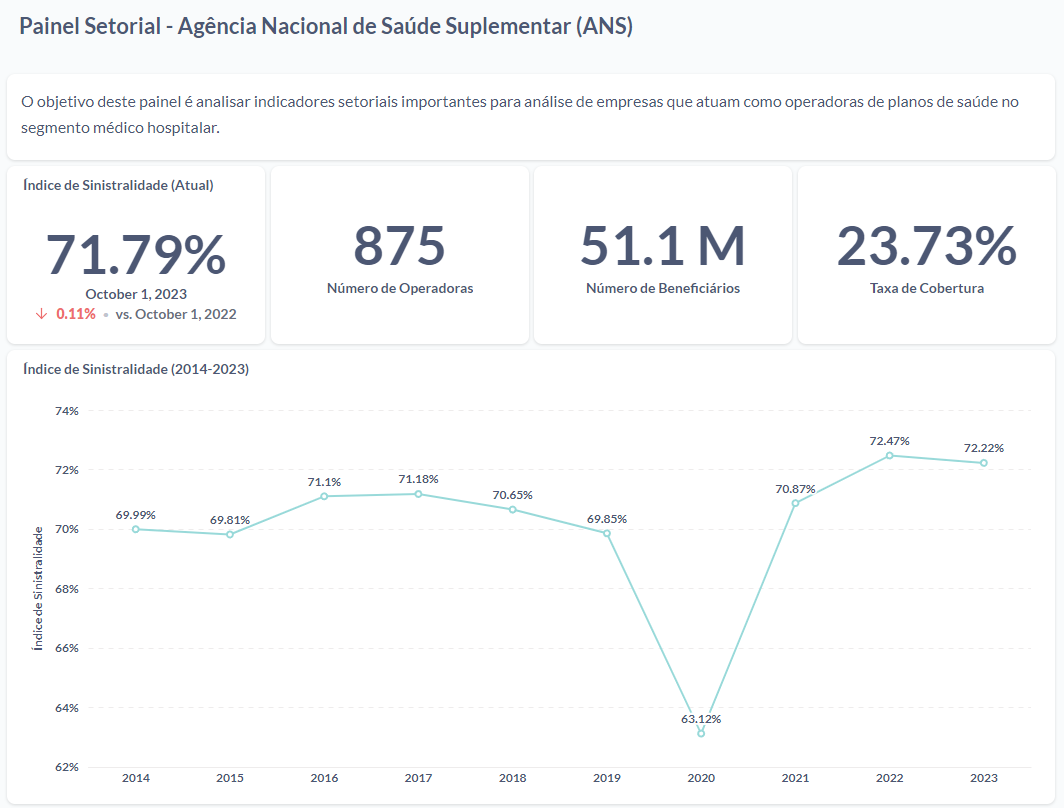
1. Qual é o atual índice de sinistralidade no setor de seguros de saúde? Ele está abaixo ou acima da média histórica?
O índice de sinistralidade é um importante indicador de rentabilidade no setor de seguros, de forma abrangente. No segmento de planos médico-hospitalares não é diferente. Esse indicador consiste na razão entre os "eventos indenizáveis" (sinistros), ou seja, despesas com assistência médica, e o total de receitas obtidas através dos planos de saúde.
Uma métrica de sinistralidade elevada indica que uma grande parte da receita está sendo gasta com os custos referentes aos sinistros, o que pode sinalizar a necessidade de reajustes ou adequação dos serviços oferecidos para garantir a sustentabilidade financeira da operadora.
Já um índice muito baixo pode indicar uma operação pouco competitiva ou a subutilização dos serviços de saúde, o que também deve ser cuidadosamente monitorado para garantir um equilíbrio justo entre a prestação de serviços e a viabilidade econômica da operadora.
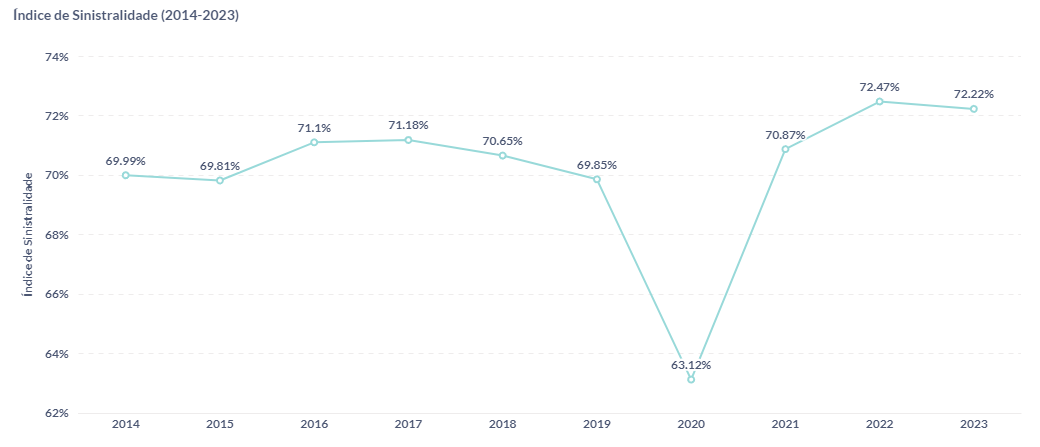
O atual índice de sinistralidade é de 71,79%, que está um pouco acima da média histórica, considerando os últimos anos.
O que chama atenção no gráfico é o ano de 2020, em que se observa uma queda fora do padrão da sinistralidade. Esse fenômeno ocorreu em razão da pandemia do COVID-19, que iniciou em 2020, e fez com que a procura por atendimentos médicos tivesse uma forte queda.
Essa constatação pode parecer contraintuitiva, mas o que observou-se foi uma redução da procura por consultas e procedimentos não emergenciais, exames de rotinas, entre outros, o que impactou na sinistralidade. Após o período do isolamento, houve um crescimento acentuado da sinistralidade, devido a demanda reprimida do período da pandemia, o que deixou muitas empresas do segmento em situação financeira pouco confortável.
2 e 3. Qual é a seguradora mais eficiente do ponto de vista de custo por beneficiário?
O custo por beneficiário é uma métria de eficiência das operadoras de planos de saúdes, que calcula o valor médio gasto pela operadora para fornecer os serviços de saúde para cada beneficiário durante um ano.
As operadoras atuam em diferentes modelos de negócio, que resultam em estruturas de custo diferentes. Modelos de negócio mais verticalizados, ou seja, operadoras que possuem seus próprios hospitais, clínicas e laboratórios, tendem a ter um controle maior sobre a operação, consequentemente sobre os custos, a qualidade dos serviços prestados e eliminando intermediários.
Outro fator que pode impactar no custo por beneficiário é o market share, que indica o tamanho da empresa no mercado em comparação aos concorrentes. O market share poder ser medido de diferentes formas, mas nesse caso está sendo considerado o número de beneficiários.
Empresas maiores, especialmente nesse setor, costumam apresentar ganhos de eficiência e vantagens competitivas, em razão do tamanho, pois a operadora pode otimizar os recursos, negociando melhores preços de medicamentos e equipamentos, em função da escala. Isso também tem grande impacto no custo por beneficiário.
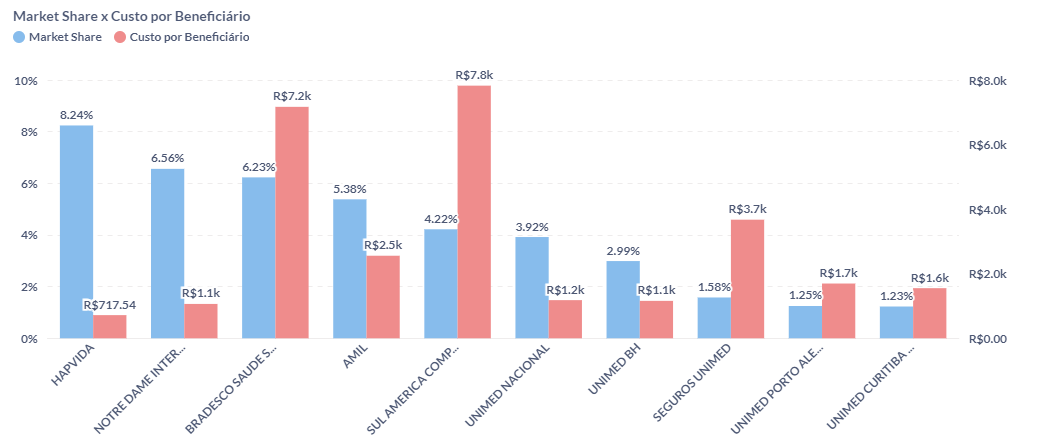
A Hapvida, que é líder do setor, recentemente adquiriu a Notre Dame Intermédica e todas sua rede hospitalar, consolidando um conglomerado de quase 15% do mercado de planos de saúde, cerca de 7,65 milhões de beneficiários.
A Hapvida x Intermédica é uma empresa verticalizada, ou seja, ela comercializa os planos de saúde e é dona dos hospitais que prestam serviço para esses planos, o que permite a empresa ter um controle muito maior sobre suas margens, além de se aproveitar dos ganhos de escala.
Esses fatores combinados são os motivos da empresa ter um dos menores custos por beneficiário do mercado, tendo o menor custo entre as 10 maiores, de apenas R$ 717,54 por beneficiário/ano.
Na ponta oposta, como exemplo, podemos citar o Bradesco Seguros, que não possui nenhum ou rede própria, e terceiriza a prestação dos serviços oferecidos pelos seus planos. O Bradesco, que atualmente é a segunda maior empresa do segmento, se consideramento a junção entre Hapvida e Intermédica, possui um custo médio por beneficiário de R$ 7.200,00 por ano.
4. Quantas empresas de plano de saúde existem no Brasil?
Atualmente, existem 850 operadoras ativas no Brasil.
5. Quantos beneficiários existem no Brasil? Qual é a taxa de cobertura?
Existem no Brasil cerca de 51 milhões de beneficiários de planos médico-hospitalares, com ou sem assistência odontológica. Se considermos o tamanho da população brasileira de cerca de 215 milhões, calculamos uma taxa de cobertura de aproximadamente 23%.
Isso significa que menos de 1/4 da população brasileira possui plano de saúde.
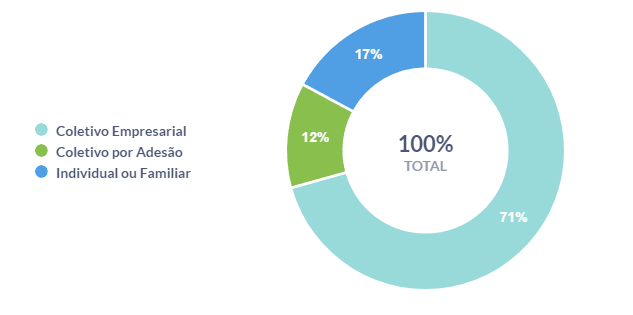
6. Existem mais planos individuais ou coletivos?
Entre os mais de 50 milhões de beneficiários, somente 17% deles possuem planos individuais ou familiares. A grande maioria dos planos são coletivos, somando 83%, sendo em grande parte planos empresariais.
Metabase
Além do ambiente do Databricks, também utilizei um ambiente de analytics criado usando Docker, PostgreSQL e Metabase, em uma instância EC2 na AWS.
Além das tecnologias mencionadas, também foi escrito um código em Python responsável por fazer a carga full-load dos arquivos parquet salvos no S3 diretamente nas tabelas do banco de dados PostgreSQL.
Mais informações podem ser encontradas no arquivo README.md dedicado exclusivamente para explicar a configuração desse ambiente.
Além de utilizar o Metabase como ambiente para realizar as consultas e produzir as visualizações, também criei um dashboard:
Conclusão
Em forma de avaliação final do projeto, considero o Databricks uma solução muito completa frente as demais opções. Apesar dos custos adicionais, o Databricks oferece muitas ferramentas para profissionais que trabalham com dados, engenheiros, cientistas e analistas de dados, que justificam os custos em razão do ganho de produtividade.
Outro ponto fundamental foi aprendizado e o contato com as funcionalidades da plataforma, que cada vez mais é adotada por empresas no mercado, mas também por permitir trabalhar em soluções mais avançadas e mais próximas do dia-a-dia das organizações. Recomendo, quem estiver ingressando na área, adquirir experiência com Databricks!
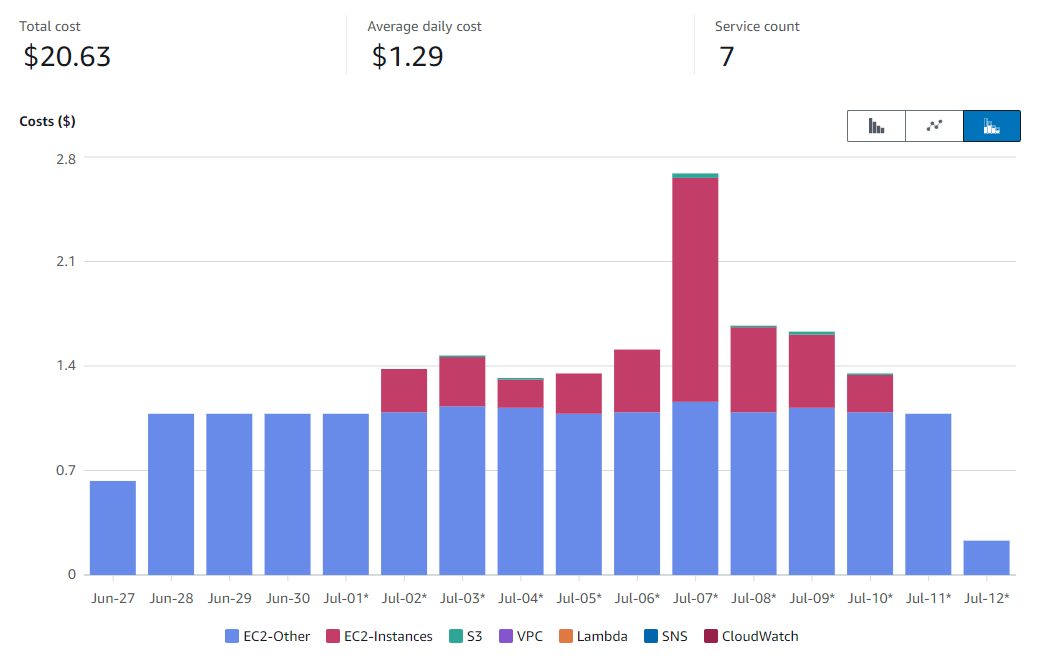
Planejei utilizar os 14 dias do free-trial do Databricks Premium integralmente e configurei um budget de cerca de R$ 150,00 para realização do projeto, conforme os custos da AWS.
No Databricks, utilizei um cluster de 4 cores e 16 GB de memória, durante todo o período, que se provou suficiente para as tarefas executadas. Principalmente, considerando um bom equilíbrio entre custo e performance.
No total, desde o dia 27 de junho, tive custo total com o projeto de $20.63 (120 reais), representado por dois serviços principais na AWS. As barras em azul representam um custo fixo essencial para o funcionamento do workspace do Databricks, que é o NAT Gateway, que atua na configuração de rede dos clusters. Já as barras na cor vermelha são, de fato, os cluster criados para execução dos workloads do trabalho.
Agradeço quem acompanhou até aqui! :)