Ciência de Dados
Fine-tuning de modelos de linguagem para análise de sentimento no mercado financeiro
28/04/2025
20 minutos
Nos mercados e na vida, grande parte das decisões ditas racionais são motivadas, na verdade, por fatores psicológicos e comportamentais ocultos. Reconhecer o efeito das emoções sob a tomada de decisão é um fator crucial, que separa bons investidores de investidores excelentes.
Existe um campo de estudo chamado "Finanças Comportamentais" que investiga como fatores psicológicos e comportamentais afetam as decisões financeiras. Esse campo é uma interseção entre finanças, psicologia e economia, e busca entender como os investidores tomam decisões e como essas decisões afetam os mercados.
Apesar do mercado financeiro global estar cada vez mais dominado por algoritmos e estratégias sistemáticas de investimento (sem intervenção humana), ainda podemos observar a forte presença dos chamados vieses comportamentais.
Esses vieses são padrões de comportamento que podem levar os investidores a tomar decisões irracionais ou sub-ótimas. Alguns exemplos de vieses comportamentais incluem:
-
Viés de confirmação: A tendência de buscar ou interpretar informações de maneira que confirme crenças ou hipóteses pré-existentes.
-
Efeito manada: A tendência de seguir o comportamento de um grupo, mesmo que isso não faça sentido do ponto de vista racional, causando a formação de bolhas ou períodos de pessimismo extremo.
-
Ancoragem: A tendência de se fixar em informações iniciais ao tomar decisões, mesmo que essas informações sejam enganosas ou não sejam mais relevantes.
-
Retrospetiva: A tendência de ver eventos passados como mais previsíveis do que realmente eram, levando a uma falsa sensação de segurança ou confiança.
Embora esses vieses sejam mais comuns entre investidores individuais, eles também podem afetar investidores institucionais e profissionais. Além disso, os mercados financeiros são influenciados por uma série de fatores externos, como notícias, eventos econômicos e mudanças políticas, que criam um ruídos capazes amplificar esses vieses.
Por isso, neste artigo, vou explorar como podemos usar modelos de linguagem para prever o sentimento do mercado financeiro, através de relatórios mensais ou trimestrais de gestores de recursos.
Essas cartas são uma fonte rica de informações sobre a perspectiva de profissionais e podem fornecer insights valiosos sobre o sentimento do mercado.
Nesse artigo, vou abordar os seguintes tópicos:
-
O que são modelos de linguagem, transformers e como podem ser usados para classificação de texto e análise de sentimento.
-
Transfer learning e fine-tuning de modelos de linguagem para adaptação a domínios específicos, como investimentos e finanças.
-
Como a técnica de PEFT (Parameter-Efficient Fine-Tuning) pode ser aplicada para treinar modelos de linguagem em tarefas específicas, como classificação de texto e previsão de sentimento.
Se você estiver interessado em ver o projeto completo, junto dos códigos, ele está disponível no meu GitHub.
Metodologia
Existem diversas formas de medir o sentimento do mercado financeiro. Uma das formas mais comuns é através de indicadores quantitativos, que são métricas numéricas que tentam capturar a temperatura do mercado.
Um termômetro quantitativo muito conhecido é o "Fear & Greed Index" da CNN, que mede o sentimento dos investidores americanos e varia entre 0 (medo) e 100 (ganância).
O índice é composto por sete indicadores, que incluem métricas de volatilidade, médias móveis, volume de ações em alta e baixa, opções de compra e venda, e o número de ações atingindo máximas e mínimas.
No dia que estou escrevendo este artigo, o índice está em 21 (medo extremo), em meio às decisões do governo Trump de impor novas tarifas sobre produtos de outros países, especialmente a China.
Outras formas de medir o sentimento do mercado envolvem o uso de dados qualitativos, como notícias, relatórios financeiros e redes sociais. Esses dados são, em grande parte, não estruturados, o que requer técnicas específicas, como processamento de linguagem natural (NLP) e inteligência artificial.
Este trabalho foi fortemente inspirado pelo artigo do Lucas Leme, que usou notícias de sites de finanças, como Valor Econômico e Infomoney, para treinar uma modelo capaz de prever o sentimento do mercado.
 Fonte: FinBERT-PT-BR: Análise de Sentimentos de Textos em Português do Mercado Financeiro
Fonte: FinBERT-PT-BR: Análise de Sentimentos de Textos em Português do Mercado Financeiro
Apesar de notícias de finanças serem uma fonte rica de informações e produzirem um grande volume de dados, ideal para tarefas como essa, elas expressam uma visão da mídia sobre o mercado, e não necessariamente a visão dos investidores.
Por isso, nesse artigo, vamos usar cartas mensais e trimestrais de gestores de recursos independentes para construir na nossa base de informações, que será usada para criar um indicador de sentimento do mercado.
Empresas de gestão de recursos, também conhecidas como gestoras ou assets, são instituições especializadas na administração profissional de ativos financeiros de terceiros. Basicamente, elas captam recursos de investidores e aplicam esses recursos em diferentes classes de ativos, como ações, títulos de renda fixa, imóveis e outros investimentos.
Essas empresas são compostas por equipes de analistas, que são liderados por um ou mais gestores responsáveis por tomar decisões de investimento e alocar os recursos de acordo com a estratégia definida.
Uma prática bastante comum entre essas empresas é a publicação periódica de cartas aos investidores, normalmente mensais ou trimestrais. Esses documentos têm o objetivo de informar sobre o desempenho dos fundos, as estratégias implementadas e as perspectivas futuras.
As cartas contêm informações valiosas sobre a visão de agentes importantes do mercado, capazes de influenciar o sentimento dos investidores. Elas são acompanhadas atentamente por empresas e acadêmicos, oferecendo uma perspectiva privilegiada sobre o ambiente de investimentos.
A primeira etapa do trabalho, portanto, foi coletar essas cartas de gestores de recursos diretamente dos seus sites. Para isso, utilizei a biblioteca BeautifulSoup para fazer o scraping dos sites das gestoras e a extração do texto dos PDFs.
Essa etapa foi bastante trabalhosa, pois as cartas estão disponíveis em diferentes formatos e layouts, o que exigiu um trabalho de limpeza e normalização dos dados. Além disso, cada gestora possui um site diferente, o que exigiu um trabalho de adaptação do código para cada site.
No total, foram coletadas 707 cartas de 12 gestoras diferentes, abrangendo o período entre 1999 e 2025. As gestoras foram escolhidas com base na sua relevância no mercado brasileiro e na disponibilidade das cartas em seus sites. Além disso, foram selecionadas gestoras independentes, que não possuem vínculo com instituições financeiras, e com viés mais voltado para ações.
A tabela abaixo mostra a quantidade de cartas coletadas de cada gestora:
| Gestora | Quantidade de cartas |
|---|---|
| Guepardo | 111 |
| IP Capital | 95 |
| Dahlia Capital | 81 |
| Dynamo | 80 |
| Kapitalo | 74 |
| Ártica | 62 |
| Encore | 58 |
| Genoa Capital | 56 |
| Alpha Key | 35 |
| Mar Asset | 20 |
| Alaska | 18 |
| Squadra | 17 |
| Total | 707 |
O texto extraído das cartas foi processado e normalizado, removendo informações irrelevantes, como tabelas, gráficos e imagens, e salvo em um banco de dados SQLite junto com outras informações, como título e data.
Transformers e Modelos de Linguagem
Os modelos de linguagem são uma classe de modelos de aprendizado profundo projetados para compreender e gerar texto. Eles são baseados na arquitetura de transformers, que foi introduzida no artigo "Attention is All You Need" em 2017.
Meu objetivo não é explicar em detalhes a arquitetura de transformers ou como esses modelos funcionam. Eu tenho certeza que você pode encontrar diversos artigos e vídeos explicando isso de forma mais didática.
Recomendo acompanhar o canal do Andrej Karpathy no YouTube, que tem um ótimo vídeo sobre a arquitetura de transformers e como ela funciona. Também recomendo um curso muito bom da Deep Learning AI, "Generative AI with LLMs", e cursos do Hugging Face.
De modo geral, esses modelos consistem em uma grande rede neural treinada em uma quantidade massiva de textos, que ao receber uma sequência de palavras, é capaz de prever a próxima palavra da sequência. Nem todos os modelos funcionam dessa forma, mas é uma boa forma de apresentar o conceito, uma vez que o modelo mais famoso, o GPT, funciona dessa forma.
Existem três tipos principais de modelos de linguagem: encoder-only, decoder-only e encoder-decoder. Modelos como o GPT, usado no ChatGPT, e Llama são decoder-only, especializados em geração de texto, a partir de um prompt. Eles são treinados usando um processo chamado de Causal Language Modeling, onde o modelo é alimentado com uma sequência de palavras e deve prever a próxima palavra. Isso significa que eles têm uma compreensão unidirecional do texto.
Outra família de modelos, os chamados de encoder-only, como o BERT, são projetados para entender o contexto de uma palavra em uma frase, levando em consideração as palavras que vêm antes e depois dela. Isso permite que o modelo capture melhor o significado das palavras e suas relações no texto.
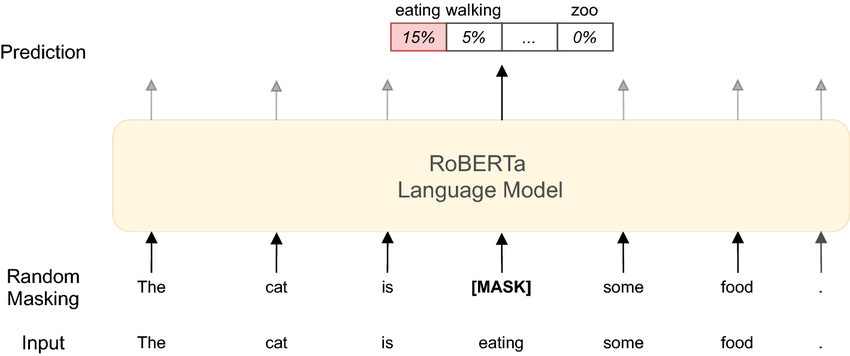
Para isso, o modelo é treinado em uma tarefa chamada de Masked Language Modeling, onde algumas palavras da sequência são mascaradas e o modelo deve prever essas palavras com base nas palavras que vêm antes e depois dela. Isso concede ao modelo uma compreensão bidirecional do texto, que beneficia tarefas como classificação de texto, resposta a perguntas e análise de sentimentos.
Esse vai ser o modelo que vamos utilizar! Ou melhor, uma versão dele chamada BERTimbau, que é uma versão do BERT do Google, só que treinado em português. O BERTimbau foi treinado pela empresa NeuralMind AI e está disponível nas versões de 110M (base) e 335M (large) parâmetros. Quanto maior o número de parâmetros, no geral, mais complexo e poderoso é o modelo.
No entanto, esse modelo não é capaz de prever o sentimento do mercado financeiro por si só. Para isso, precisamos treinar ele em uma tarefa específica, que nesse caso é a classificação de texto. Além disso, não é um modelo que foi treinado especificamente para o domínio financeiro, e nem é um Large Language Model (LLM) com bilhões de parâmetros, o que pode limitar sua capacidade de entender o contexto e o significado das palavras nesse domínio.
Portanto, usaremos o BERTimbau como um modelo base e faremos um processo chamado de transfer learning, seguindo duas etapas:
-
Domain-Adaptive Pretraining (DAPT): O pré-treinamento do modelo será continuado usando uma grande quantidade de textos sobre finanças, o que permite que ele aprenda a entender o contexto e o significado de novas palavras nesse domínio. Isso é feito através de um processo chamado domain-adaptive pretraining (DAPT), onde o modelo é treinado em uma tarefa geral (como previsão de palavras).
-
Task Fine-tuning: O modelo é ajustado para uma tarefa específica, que nesse caso é a classificação de texto e previsão de sentimento. Isso é feito através de um processo chamado task fine-tuning, onde o modelo é exposto a um conjunto de dados rotulados, permitindo que ele aprenda a identificar corretamente o sentimento de forma mais assertiva.
Fine-tuning para adaptação de domínio
O objetivo dessa etapa é ensinar o nosso modelo tudo que ele precisa saber sobre finanças e investimentos. Antes de delegar qualquer tarefa para um ser humano, como classificar o sentimento de um texto, é importante que ele tenha uma boa base de conhecimento sobre o assunto. O mesmo vale para um modelo de linguagem.
Para entender corretamente um texto sobre finanças, o modelo precisa conhecer palavras e jargões específicos do domínio, como "renda fixa", "juros", "ações", "Banco Central", "volatilidade", "alpha", "beta", entre outros. Além disso, o modelo precisa entender o contexto em que essas palavras são usadas e como elas se relacionam entre si.
Como nosso modelo base possui apenas 110M de parâmetros, não devemos esperar que ele tenha um conhecimento profundo sobre domínios específicos, como outros modelos mais capazes. Diante da expressão "bull market", por exemplo, o nosso modelo pode não entender que isso se refere a um mercado em alta, e sim a um mercado de touros.
Apesar do exemplo ser cômico, essa etapa é fundamental para garantir que o modelo tenha boa acurácia na tarefa de previsão de sentimento e tenha baixo risco de ter alucinações.
Para realizar o domain-adaptive pretraining, usamos a mesma tarefa de Masked Language Modeling que o BERTimbau foi treinado inicialmente, mas agora usando um conjunto de dados específico do domínio financeiro. No nosso caso, vamos usar trechos extraídos das cartas das gestoras de recursos. No total, foram usados 36.000 trechos, com em média 200 caracteres cada.
O código para essa etapa está disponível no repositório do projeto. Utilizei uma instância de GPU da AWS (g4dn.xlarge) para treinar o modelo, que levou cerca de 2 horas para ser treinado. O treinamento foi feito usando a biblioteca Transformers do Hugging Face.
O resultado do modelo adaptado para o domínio é muito interessante!
from transformers import AutoModelForMaskedLM, AutoTokenizer
from transformers import pipeline
base_model = AutoModelForMaskedLM.from_pretrained('neuralmind/bert-base-portuguese-cased')
domain_adapted_model = AutoModelForMaskedLM.from_pretrained('../models/bert-portuguese-asset-management')
tokenizer = AutoTokenizer.from_pretrained('neuralmind/bert-base-portuguese-cased', do_lower_case=False)
def predict_mask(text: str, model: str, top_k: int = 5):
fill_mask = pipeline("fill-mask", model=model, tokenizer=tokenizer, top_k=top_k)
outputs = fill_mask(text)
for o in outputs:
token = o["token_str"].strip()
score = o["score"]
print(f" {token:15s} → {score:.4f}")
prompt = "Houve um debate interno sobre alocar mais recursos em [MASK]."
print("======= Base Model =======\n")
predict_mask(prompt, base_model, top_k=5)
# ======= Base Model =======
#
# educação → 0.0856
# projetos → 0.0781
# saúde → 0.0671
# hospitais → 0.0483
# infraestrutura → 0.0477
print("\n=== Domain Adapted Model ===\n")
predict_mask(prompt, domain_adapted_model, top_k=5)
# === Domain Adapted Model ===
#
# ações → 0.3805
# empresas → 0.0754
# juros → 0.0431
# investimentos → 0.0409
# infraestrutura → 0.0288
Podemos observar, ao usar ambos os modelos para inferência, que o modelo adaptado tem uma compreensão muito melhor do contexto e é capaz de prever palavras mais relevantes para o domínio financeiro. O modelo base completa a frase com palavras como "educação", "saúde" e "hospitais", enquanto o nosso modelo adaptado completa a frase com palavras como "ações", "empresas" e "juros".
Isso mostra que o modelo adaptado tem um conhecimento mais profundo sobre o domínio financeiro, é capaz de entender melhor o contexto em que as palavras são usadas e, por fim, analisar melhor o sentimento.
Essa é uma forma de entender o impacto do domain-adaptive pretraining no modelo. Há também métricas para avaliar o desempenho do modelo, como a perplexidade.
A perplexidade corresponde à exponencial da entropia-cruzada ou perda (loss) sobre os dados de teste. Quanto menor a perplexidade, melhor o modelo: ele está menos “perplexo” (menos incerto) sobre qual token deve ser usado para preencher a [MASK].
| Modelo Base (BERTimbau) | Modelo Adaptado ao Domínio | |
|---|---|---|
| Perplexity | 10.95 | 4.29 |
A perplexidade do modelo base obtida foi de 10.95, enquanto a perplexidade do modelo adaptado foi 4.29 no conjunto de dados de teste, ou seja, dados que não foram vistos durante o treinamento. Isso mostra que nosso objetivo foi atingido: o modelo adaptado tem uma compreensão muito melhor do domínio financeiro e é capaz de prever palavras com mais precisão.
PEFT e tarefas específicas
A segunda etapa é "ensinar" ao modelo como classificar o sentimento de um texto. Vamos usar o modelo adaptado para o domínio financeiro que treinamos e ajustá-lo para a tarefa de classificação de texto.
O nosso modelo, até o momento, é capaz de carregar informação contextual de um texto e reconstruir tokens mascarados. Para realizar a tarefa de classificação de texto, precisamos adicionar uma camada de classificação ao modelo. Essa camada é muitas vezes chamada de "cabeça de classificação" e é responsável por mapear a saída do modelo para as classes de sentimento que queremos prever.
De forma simples, a cabeça de classificação consiste em uma camada adicional da nossa rede neural, que aplica uma função de ativação linear para obter logits (valores não normalizados) para cada classe de sentimento. Esses logits passam por uma função de ativação softmax, que os converte em probabilidades para cada classe.
Por fim, a classe com a maior probabilidade é escolhida como a previsão do modelo. Ao final do treinamento, nosso modelo deve receber um texto e retornar um output conforme abaixo:
[
{
"label": "NEGATIVO",
"score": 0.85
},
{
"label": "NEUTRO",
"score": 0.10
},
{
"label": "POSITIVO",
"score": 0.05
}
]
Para o treinamento, são necessários dados rotulados, como exemplos de textos positivos, negativos e neutros. A quantidade de dados é um fator importante para o desempenho do modelo e, no geral, quanto mais dados rotulados, melhor o desempenho do modelo.
Portanto, realizei o pré-processamento das cartas coletadas, normalizando os textos e transformando-os em exemplos de treinamento com em média 200 caracteres. Criei um amostra aleatória de 1.000 exemplos por amostragem simples (não-estratificada) e rotulei cada exemplo manualmente, em três classes: "POSITIVO", "NEGATIVO" e "NEUTRO". Esse é o nosso dataset de treinamento para tarefa de classificação.
Em processos mais robustos, alguns cuidados precisariam ser tomados para garantir um melhor desempenho do modelo:
-
Amostragem Estratificada: A amostragem estratificada é uma técnica de amostragem que garante que cada classe esteja representada na amostra de treinamento. Isso é importante porque algumas gestoras possuem muito mais cartas do que outras, o que pode levar a um viés no modelo, fazendo com que ele se especialize em um grupo de gestoras específicas e seu formato de escrita.
-
Balanceamento de Classes: O balanceamento de classes é uma técnica que garante que cada classe tenha o mesmo número de exemplos na amostra de treinamento. Isso é importante porque algumas classes podem ter mais exemplos do que outras, o que pode levar a outro viés no modelo. Por exemplo, se grande parte dos exemplos são da categoria "NEUTRO", por se tratarem de informações técnicas ou factuais, nosso modelo pode aprender a prever essa classe com mais frequência.
-
Mais anotadores: O ideal é ter mais de um anotador rotulando os dados, para garantir que as anotações sejam consistentes e precisas. A rotulação manual é uma tarefa subjetiva e pode variar de acordo com o anotador, por isso, uma boa prática é usar o índice de concordância entre os anotadores, como o Kappa de Cohen, para medir a concordância entre os anotadores e garantir que as anotações sejam consistentes, e contar com o auxílio de profissionais da área.
Apesar de estar ciente dessas melhores práticas, optei por seguir de forma mais simples, uma vez que o objetivo do projeto é apenas demonstrar a técnica de fine-tuning e não necessariamente criar um modelo de produção. A anotação, como disse, foi feita de forma manual, portanto incluindo um viés humano e pessoal, e não necessariamente refletindo o sentimento do mercado.
Com os devidos cuidados e processos, é possível usar essa técnica para criar um modelo de produção, capaz de prever o sentimento do mercado financeiro com alta acurácia e que tenha utilidade prática para analistas de investimentos e gestores.
Aqui estão alguns exemplos de trechos rotulados como positivos e negativos:
POSITIVO
-
"Apesar de não termos controle sobre a rentabilidade de curto prazo, estamos muito satisfeitos com nossos investimentos – seja para que lado for a política."
-
"É difícil nos lembrarmos de uma época que conseguíamos compor carteiras de ações com um perfil de retorno e risco tão interessantes quanto atualmente."
-
"Apesar da nova lei ainda não ter sido aprovada, a discussão em torno dela acabou produzindo uma série de efeitos positivos que podem vir a causar um impacto muito favorável no mercado de capitais do Brasil."
NEGATIVO
-
"Sem contar com o fato de que, por imitação, no mais tradicional efeito manada, a atitude racional agora parece ser vender a qualquer preço."
-
"O cenário atual é desafiador principalmente para os investidores que necessitem de geração contínua de renda, como aposentados e regimes de previdência."
-
"Acima de tudo, embora estejamos muito cautelosos e preocupados com o mercado, temos convicção de que estamos fazendo as coisas certas."
-
"Há ainda muita desconfiança sobre a capacidade de o novo governo executar o ajuste fiscal e qual a velocidade do mesmo."
Os trechos positivos, no geral, representam sentimentos de otimismo, confiança e esperança em relação ao mercado e à economia. Já os trechos negativos representam sentimentos de pessimismo, desconfiança, medo e incerteza.
Após criar o dataset rotulado, o próximo passo foi treinar o modelo. Para isso, utilizei uma técnica de PEFT (Parameter-Efficient Fine-Tuning), chamada LoRA (Low-Rank Adaptation), que permite ajustar modelos de linguagem pré-treinados para tarefas específicas de forma otimizada, utilizando um número reduzido de parâmetros.
O processo de fine-tuning é muito intensivo em memória. Além dos parâmetros do modelo, que podem ser centenas de bilhões, é preciso armazenar os gradientes de cada parâmetro, otimizadores e outros estados intermediários. Isso pode levar a um consumo massivo de memória, especialmente em GPUs com pouca memória ou máquinas locais.
A técnica LoRA "congela" um certo número de parâmetros, permitindo que o modelo seja treinado em GPUs com menos memória e ambientes de menor poder computacional. As técnicas de PEFT atuam em parâmetros de camadas específicas da rede neural, permitindo que o modelo seja ajustado para tarefas específicas sem a necessidade de treinar todos os parâmetros do modelo.
Apesar do nosso modelo não ser tão grande, o uso de LoRA é interessante, pois reduz o tempo de treinamento e o consumo de memória, preservando ainda grande parte da performance no modelo final.
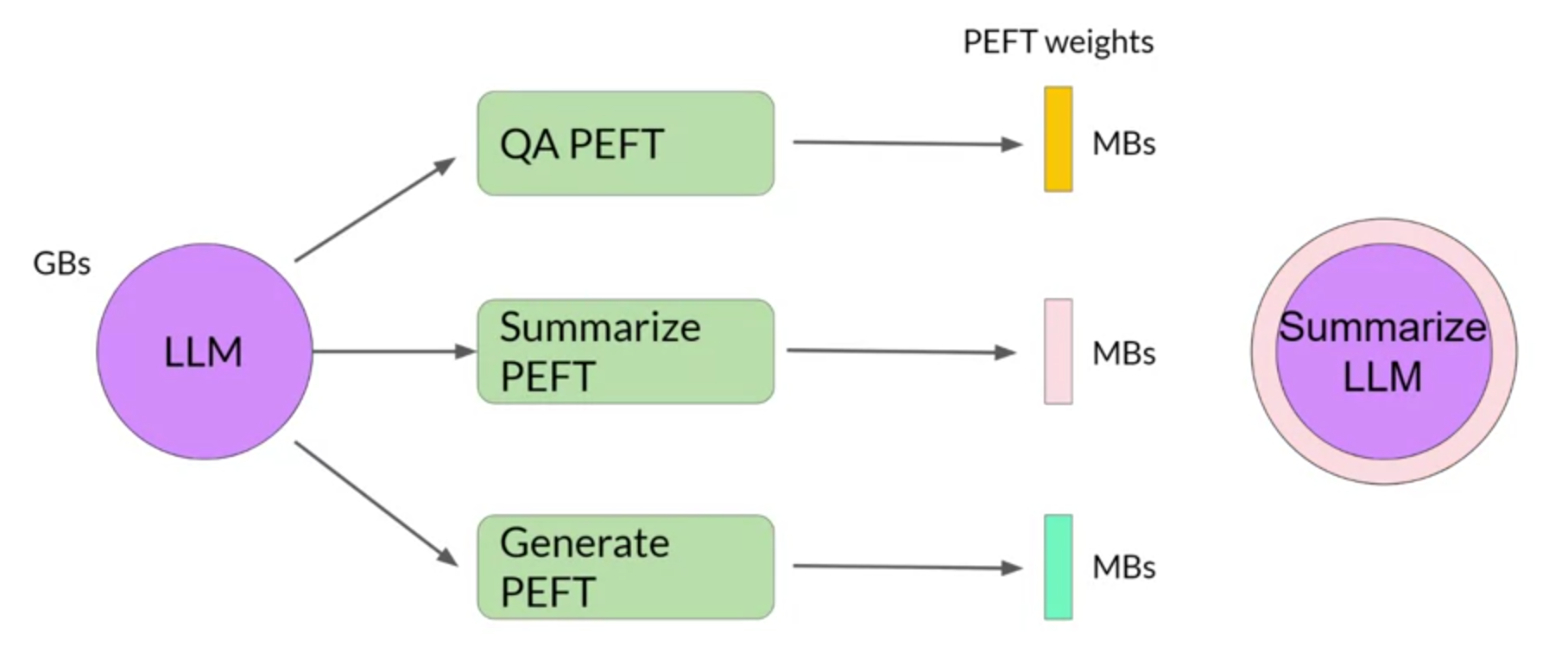
O resultado desse processo não é um novo modelo treinado, mas sim um adaptador que é combinado ao modelo base, contendo novos parâmetros ou novas camadas. Esse adaptador contém os parâmetros ajustados para a tarefa específica e pode ser carregado junto com o modelo base para realizar a tarefa de classificação.
Dessa forma, o modelo base permanece inalterado e pode ser reutilizado em outras tarefas, enquanto o adaptador pode ser treinado e ajustado para a tarefa específica. Podem ser treinados múltiplos adaptadores para diferentes tarefas, permitindo que o mesmo modelo base seja usado para várias tarefas diferentes. Os adaptadores são muito menores que o modelo base e podem ser armazenados separadamente e carregados conforme necessário.
Da mesma forma que o treinamento anterior, utilizei um servidor remoto com uma instância de GPU e o código para o treinamento está disponível no repositório do projeto. Utilizei a biblioteca PEFT do Hugging Face e, ao todo, o modelo foi treinado em somente 1,181,955 parâmetros, pouco mais de 1% do número de parâmetros do modelo base.
Ao final do treinamento, é possível combinar o modelo base com o adaptador treinado, criando um novo modelo que pode ser usado para realizar a tarefa de classificação de texto. O modelo final pode ser acessado no meu perfil do Hugging Face Hub.
Avaliação do modelo
Na etapa de avaliação, comparei o nosso modelo (Modelo AM) com outro modelo treinado nos mesmos dados, adicionando uma cabeça de classificação ao BERTimbau, usando um conjunto de dados de teste. O conjunto de dados de teste foi separado do conjunto de dados de treinamento e não foi usado durante o treinamento do modelo.
O objetivo dessa comparação é avaliar o quanto o domain-adaptive pretraining melhorarou o desempenho do modelo em relação ao modelo base. Para isso, utilizei as métricas de acurácia e F1 Score.
Além do modelo base, também comparei com o FinBERT-PT-BR, mencionado no início do artigo, que também é um modelo de linguagem pré-treinado para o domínio financeiro e baseado em BERT usado para previsão de sentimento.
| Modelo | Accuracy | F1 Score |
|---|---|---|
| Modelo AM | 0.7300 | 0.4582 |
| FinBERT-PT-BR | 0.4800 | 0.3401 |
| BERTimbau | 0.3200 | 0.2249 |
Observamos que o Modelo AM superou significativamente o BERTimbau, que não passou pela adaptação ao domínio financeiro, evidenciando como o domain-adaptive pretraining é essencial para aprimorar o desempenho em tarefas específicas.
Também podemos ver que o FinBERT-PT-BR teve um desempenho pior que o nosso modelo. Isso pode ser explicado pelo fato do FinBERT-PT-BR ter sido treinado em um conjunto de dados diferente (notícias) e não necessariamente reflete o mesmo domínio.
O objetivo foi criar um modelo que fosse capaz de prever o sentimento do mercado financeiro a partir de cartas de gestoras de recursos, e não necessariamente um modelo que fosse capaz de prever o sentimento do mercado geral ou da mídia.
Apesar de ter superado os modelos de comparação, o desempenho do nosso modelo ainda não é ideal. A acurácia de 73% e o F1 Score de 45% indicam que o modelo ainda tem espaço para melhorias.
Um ponto de melhoria que poder ser considerado "low hanging fruit" é aumentar a quantidade de dados rotulados e o tempo de treinamento. Se aumentarmos o número de exemplos rotulados para 5.000 ou 10.000, por exemplo, podemos esperar um aumento significativo no desempenho do modelo. Combinado com o uso de outros anotadores, haveria um salto qualitativo muito grande.
Uma constatação menos óbvia é com relação ao desbalanceamento das classes. Em nosso conjunto de dados de treino, 67% do total de exemplos foram rotulados como NEUTRO. Isso é um problema, pois o modelo pode aprender a prever essa classe com mais frequência, levando a um viés na classificação.
De fato, boa parte de uma texto, como um relatório de gestão, é neutro, mas o ideal é equilibrar as classes, através de um processo de undersampling. Essa estratégia reduziria drasticamente o número total de exemplos rotulados, portanto, a técnica utilizada para mitigar o efeito do desbalanceamento foi a pesagem de classes. Essa técnica consiste em atribuir pesos diferentes para cada classe, de forma que o modelo penalize mais os erros nas classes menos representadas (POSITIVO e NEGATIVO).
Isso pode ser feito através de uma função de perda customizada:
class WeightedTrainer(Trainer):
def compute_loss(self, model, inputs, num_items_in_batch=None, return_outputs=False):
labels = inputs.get("labels")
# forward pass
outputs = model(**inputs)
logits = outputs.get("logits")
# define class weights (classes 0 and 1 are penalized twice as much as class 2)
class_weights = torch.tensor([2.0, 2.0, 1.0], device=logits.device)
# create the weighted cross entropy loss
loss_fct = torch.nn.CrossEntropyLoss(weight=class_weights)
loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))
return (loss, outputs) if return_outputs else loss
Durante a fase de experimentação, o ajuste da função de perda contribuiu positivamente para a melhoria do modelo, especialmente considerando a métrica F1 Score, que é mais adequada para avaliar o desempenho de modelos em tarefas de classificação desbalanceadas.
O uso dessas técnicas, combinado com o aumento da quantidade de dados rotulados e a utilização de mais anotadores, pode levar a um desempenho muito melhor.
Feitas essas considerações, agora já podemos usar o nosso modelo para fazer inferência, ou seja, prever o sentimento de um texto. Podemos usá-lo, por exemplo, para criar um indicador de sentimento do mercado financeiro, a partir das cartas de gestores de recursos, desde 1999.
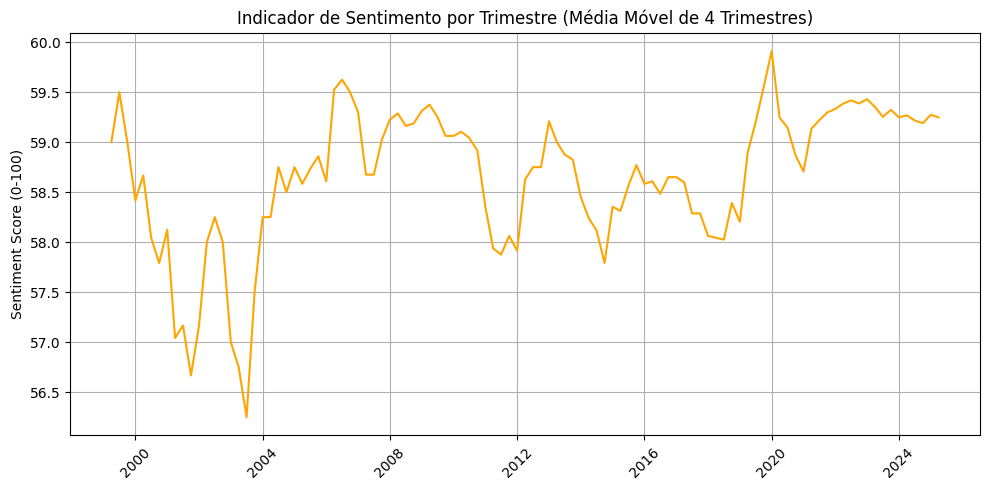
Para chegar nesse resultado, foi atribuído um score de sentimento para cada carta e calculado um sentimento médio por trimestre, que costuma ser a periodicidade das cartas, acompanhando a divulgação dos resultados financeiros das empresas.
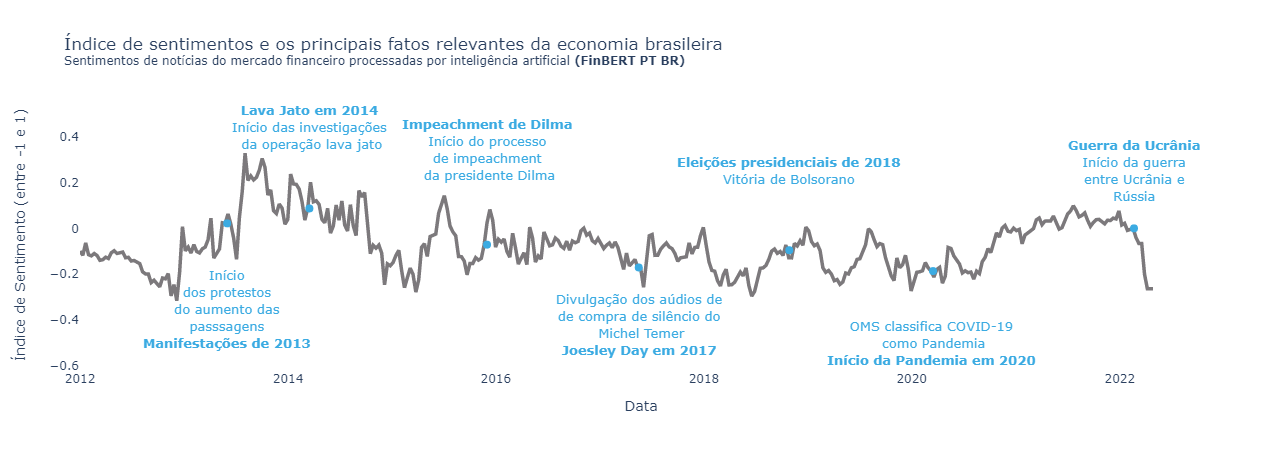
O gráfico mostra uma média móvel de 12 meses do sentimento do mercado financeiro, que varia entre 0 (muito negativo) e 100 (muito positivo). A série temporal apresenta grandes variações, principalmente nos início dos anos 2000, em que foram coletadas poucas cartas.
Para chegar ao valor da métrica, entre 0 e 100, utilizei as probabilidades retornadas pelo modelo, eliminando os valores neutros e normalizando os valores positivos e negativos. O valor para cada carta é calculado da seguinte forma:
def _aggregate(prob_chunks: List[List[Dict[str, float]]]) -> int:
if not prob_chunks:
return 50
scores, weights = [], []
for chunk in prob_chunks:
d = {x["label"]: x["score"] for x in chunk}
p_pos, p_neg = d["POSITIVE"], d["NEGATIVE"]
s_i = p_pos - p_neg
w_i = p_pos + p_neg
if w_i:
p_pos, p_neg = p_pos / w_i, p_neg / w_i
s_i = p_pos - p_neg
scores.append(s_i)
weights.append(w_i)
S = np.dot(scores, weights) / sum(weights) if weights else 0.0
S = np.sign(S) * abs(S) ** 0.75 # alpha = 0.75
return int(50 * (S + 1)) # [-1,1] -> [0,100]
Apesar das variações, é possível observar alguns padrões interessantes e certamente é uma metodologia promissora e com boa margem para melhorias.
Conclusão
Este trabalho mostrou que, mesmo em um mercado cada vez mais quantitativo, as emoções e o comportamento humano ainda têm um peso enorme — e que, com as ferramentas certas, podemos tentar capturá-los.
Adaptamos um modelo de linguagem para compreender o vocabulário financeiro e, em seguida, ensinamos a ele a tarefa de classificar cartas de gestores a partir do seu sentimento.
A despeito dos desafios, como a limitação no volume de dados rotulados e o desbalanceamento entre classes, conseguimos criar um modelo com resultados bastante promissores.
A partir dele, montamos um indicador de sentimento de mercado ao longo de mais de duas décadas, revelando padrões interessantes — e abrindo espaço para muitas possibilidades.
O experimento prova que dá para tirar muito valor das novas técnicas que vem surgindo em inteligência artificial, aproximando tecnologia e mercado financeiro com resultados tangíveis.
Vale mencionar que utilizei um servidor remoto na AWS para realizar todo treinamento dos modelos. É uma experiência muito interessante, que se aproxima bastante do dia-a-dia dos pesquisadores de IA que lidam com grandes modelos de linguagem (LLMs).
Todo treinamento foi feito em uma instância de g4dn.xlarge, que possui 16 GB de memória (VRAM) e 4 núcleos de GPU. Ela já vem configurada com os principais frameworks de aprendizado profundo, como TensorFlow e PyTorch, e os drivers necessários da NVIDIA. No entanto, para garantir a reprodutibilidade, fiz todo o setup do ambiente usando Docker.
Meu custo total, incluindo um certo período de aprendizado e experimentação, foi de $18.14 (aproximadamente R$108,84).
Como um todo, o projeto foi muito interessante e me ensinou bastante sobre modelos de linguagem, as técnicas de transfer learning e as ferramentas do ecossistema do Hugging Face. Espero que tenha sido útil para você também!
Agradeço quem leu até aqui e espero que tenha gostado do artigo. Se você tiver alguma dúvida ou sugestão, fique à vontade para entrar em contato comigo através do meu e-mail, LinkedIn ou Twitter.