Ciência de Dados
Machine Learning aplicado à predição de fraudes em cartões de crédito
13/01/2025
12 minutos
Imagine a seguinte situação. Você acorda de manhã e decide ir até a padaria tomar café da manhã. Ao terminar de comer, se dirige ao caixa para pagar, desbloqueia o telefone para pagar por aproximação usando uma carteira digital, mas sua compra é negada.
Em outro momento, você decide aproveitar as promoções de fim de ano em determinada plataforma de e-commerce. Preenche os dados e informações do seu cartão, mas sua compra não pode ser efetuada e você nota uma mensagem pedindo que entre em contato com o seu banco.
Embora você tenha certeza que possui saldo suficiente na conta ou limite de crédito para realizar a compra, por algum motivo sua transação não é concluída. Isso ocorre porque, todos os anos, mais de 30 bilhões de dólares são movimentados em transações fraudulentas de cartões de crédito e as empresas que prestam esses serviços, como bancos e instituições de pagamento, investem pesado em sistemas de prevenção de fraude.
Apesar de nem sempre serem assertivos, como nos casos descritos acima, em que houveram falsos positivos, esses sistemas podem evitar uma grande dor de cabeça para os clientes e para essas instituições.
A fraude em transações do tipo "Card Not Present" (CNP) ocorre quando compras são realizadas sem a presença física do cartão de crédito. Com o avanço da tecnologia e a popularização das compras pela internet, esse tipo de transação tornou-se predominante.
No Brasil, por exemplo, 61% dos consumidores preferem comprar online em vez de em lojas físicas, e 78% realizam pelo menos uma compra mensal pela internet. Nessas compras, os consumidores inserem os dados do cartão, como número, data de validade e código de segurança, ou utilizam carteiras digitais em dispositivos móveis, facilitando as transações, mas também aumentando os riscos de fraude.
Considerando esse cenário, o objetivo desse artigo é apresentar o processo de treinamento de um modelo de classificação capaz de estimar a probabilidade de transações serem fraudulentas e tomar decisões entre aprovar ou rejeitar a transação. Em paralelo, também discutir conceitos importantes desse tipo de problema, como classes desbalanceadas, redução de dimensionalidade e uso adequado de métricas.
IEEE-CIS Fraud Detection
Os dados foram preparados e disponibilizados pela IEEE Computational Intelligence Society e lançados durante uma competição "IEEE-CIS Fraud Detection" no Kaggle.
O que torna este projeto ainda mais interessante é o fato dos dados utilizados serem provenientes de transações reais, que foram fornecidos pela Vesta Corporation. A Vesta é uma empresa especializada em soluções de proteção contra fraudes e processamento de pagamentos para transações móveis e online.
A empresa utiliza modelos avançados de machine learning para analisar mais de US$ 4 bilhões em transações anualmente, fornecendo serviços que permitem a aprovação de vendas em milissegundos e o processamento de pagamentos em mais de 40 países.
O conjunto de dados possui cerca de 600.000 registros e contém mais de 430 características. Portanto, além do desafio de modelagem para predição de fraudes, é preciso considerar o grande volume de dados e a alta dimensionalidade. Por serem transações reais, a maior parte das features foi anonimizada, garantindo a privacidade dos clientes. Portanto, não é possível saber qual o conteúdo real de todas as variáveis.
Os dados de treinamento do Kaggle estão divididos em dois arquivos .csv. O primeiro possui dados sobre as transações, como valor transacionado, números do cartão, localização e produto transacionado. O segundo arquivo possui dados de identificação, como tipo de dispositivo usado, sistema operacional, dados de conexões com internet, versão do navegador, etc. As duas tabelas são unidas pela chave TransactionID.
A variável target, ou seja, que queremos prever é isFraud (0 ou 1) tratando-se de um problema de classificação binária. Em nosso conjunto de dados, a classe positiva (isFraud = 1) representa apenas 3,5% do conjunto total de treinamento. Portanto, temos diante de nós um problema com classes desbalanceadas.
Em meu último artigo, escrevi sobre os "Desafios na construção de classificadores robustos em conjuntos de dados desbalanceados". Apresentei algumas técnicas para lidar com esse tipo de problemas em tarefas de ML, como reamostragrem, ajustes nos pesos das classes e o bom uso das métricas de avaliação.
Quando há desbalanceamento de classes é fundamental conhecer as principais técnicas para lidar com esse problema de forma eficiente.
A acurácia, por exemplo, é uma métrica muito usada em problemas gerais, mas que não tem grande utilidade para essa situação específica. Imagine que o modelo aprenda a dizer que todas as transações são verdadeiras, ele estaria certo a maioria das vezes e a acurácia seria próxima de 97%, mas o modelo seria muito ruim.
Métricas mais adequadas nesses casos são precisão e recall, que juntas formam o F1-score. Essas métricas são calculadas a partir do número de falsos positivos ou falsos negativos e verdadeiros positivos.
Assim, podemos ajustar nosso modelo mais adequadamente para nosso objetivo alvo: minimizar falsos positivos (recall) ou minimizar falsos negativos (precisão). Vamos discutir essa diferença mais profundamente ao longo do artigo.
Além da precisão, recall e métricas da família F-score, a competição do Kaggle utiliza como benchmark o ROC AUC. Portanto, também vamos utilizar essa métrica como referência para comparar o modelo treinado com outras soluções desenvolvidas pelos competidores, usando os mesmos dados.
A curva ROC representa graficamente a relação entre a taxa de verdadeiros positivos (TPR) e a taxa de falsos positivos (FPR) para diferentes limiares de decisão. O valor do ROC AUC é representado pela área sob a curva e varia entre 0 e 1, onde 0,5 indica um modelo aleatório, e 1 representa um modelo perfeito.
Redução de dimensionalidade (PCA)
Por se tratat de quase 600.000 registros e 400 variáveis, uma das técnicas usadas durante a etapa de exploração dos dados e experimentação foi a criação de uma amostra estratificada de 10% do conjunto original com objetivo de reduzir o tempo de treinamento dos modelos.
Isso permite testar diversas combinações em menos tempo. Depois que estivermos satisfeitos com modelo escolhido e os parâmetros, podemos utilizar o dataset completo para treinar o modelo final. Além disso, permite realizar transformações em matrizes de modo que a máquina consiga processar os dados sem exceder seus limites de memória.
A amostragem estratificada é uma técnica que permite criar subgrupos homogêneos (estratos) com base em características relevantes para o estudo. Nesse caso, é fundamental manter a proporção de fraudes e transações verdadeiras ou poderíamos correr o risco de criar uma amostra aleatória em que o desbalanceamento das classes fosse ainda mais acentuado.
Também foi utilizada uma técnica para reduzir o número de features usadas para treinar o modelo. Por serem muito numerosas, o alto número de features exige maior poder computacional e interfere na capacidade do modelo de generalizar bem os dados.
Para isso, utilizei a técnica de Análise de Componentes Principais (PCA), que permite transformar as features originais em um novo conjunto de variáveis não correlacionadas, chamadas de componentes principais.
Esses componentes são ordenados de forma a capturar a maior variância possível dos dados nas primeiras dimensões, permitindo que descartemos as componentes menos relevantes. Assim, consigo reduzir a complexidade do modelo, preservando a maior parte da informação contida nas features originais.
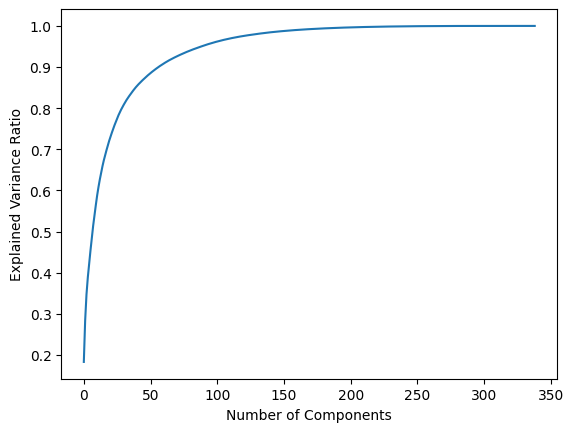
O gráfico acima mostra a variância explicada acumulada em função do número de componentes principais, após utilizar o PCA. Inicialmente, a variância explicada aumenta rapidamente com o acréscimo dos primeiros componentes. Isso indica que esses componentes capturam a maior parte da variância dos dados.
Conforme mais componentes são adicionados, o crescimento da variância explicada desacelera, porque os componentes adicionais capturam porções cada vez menores da variância. Cerca de 50 a 60 componentes explicam uma grande fração da variância total (provavelmente mais de 90%).
Sendo assim, podemos determinar uma fração aceitável da variância (95%, por exemplo) e determinar quantos componentes são necessários para capturar essa fração.
Dessa forma, é possível reduzir o dataset de muitas dimensões para apenas um número reduzido, otimizando o desempenho dos algoritmos e os recursos necessários para treiná-los.
Precisão vs. Recall
Uma das decisões mais críticas no desenvolvimento de algoritmos de detecção de fraudes em cartões de crédito é encontrar o equilíbrio ideal entre precisão e recall. Essa talvez seja a ideia mais importante que eu gostaria de abordar nesse artigo.
Imagine um médico realizando exames de rotina. Em cada paciente, ele precisa decidir se deve ou não indicar um tratamento com base nos sintomas observados. Se ele for muito cauteloso e indicar o tratamento ao menor sinal de doença, raramente deixará passar um caso grave (alto recall), mas muitos pacientes saudáveis receberão tratamentos desnecessários (baixa precisão).
Por outro lado, se ele só indicar o tratamento quando tiver certeza absoluta do diagnóstico, poucos pacientes saudáveis serão tratados sem necessidade (alta precisão), mas alguns casos graves podem passar despercebidos (baixo recall).
Em detecção de fraudes, enfrentamos o mesmo dilema. A precisão nos diz quantas transações classificadas como suspeitas eram realmente fraudes. O recall nos mostra quantas fraudes reais conseguimos identificar. Como no caso do médico, não existe decisão perfeita - aumentar um significa inevitavelmente reduzir o outro.
Quando o modelo erra ao classificar uma transação legítima como fraude (falso positivo), criamos um inconveniente para o cliente. Ele pode ter seu cartão bloqueado durante uma compra importante ou precisar responder perguntas de verificação. Irritante? Sim. Catastrófico? Não.
Agora, considere o cenário oposto: uma fraude real que passa despercebida pelo modelo (falso negativo). O prejuízo pode ser substancial. Não é apenas o valor financeiro em jogo, mas também a confiança do cliente na instituição. As pessoas tendem a ser mais compreensivas com um excesso de zelo em segurança do que com uma falha em proteger seu dinheiro.
Esse dilema é um desafio constante para as instituições financeiras e deve ser analisado com base no entendimento do negócio. Em minha visão, se perguntarmos aos clientes de um banco, a maioria provavelmente preferiria nunca ser vítima de uma transação fraudulenta, mesmo que isso implique, ocasionalmente, ter uma ou outra transação bloqueada ou precisar passar por uma verificação de segurança adicional.
Com essa premissa em mente, o objetivo é desenvolver um modelo que priorize um bom recall, buscando identificar a maioria das fraudes, sem comprometer excessivamente a precisão.
É aqui que entra o F2-score, uma métrica que entende essa assimetria de custos. Diferente de sua versão mais conhecida, o F1-score, o F2 dá um peso maior ao recall. É como se dissesse: "Sim, precisão é importante, mas não perder fraudes reais é ainda mais importante."
Observando os gráficos abaixo, vemos claramente essa dinâmica em ação. A primeira imagem mostra como precisão e recall se movem em direções opostas. É impossível maximizar ambos. Modelos diferentes possuem comportamentos diferentes em relação a essas métricas.
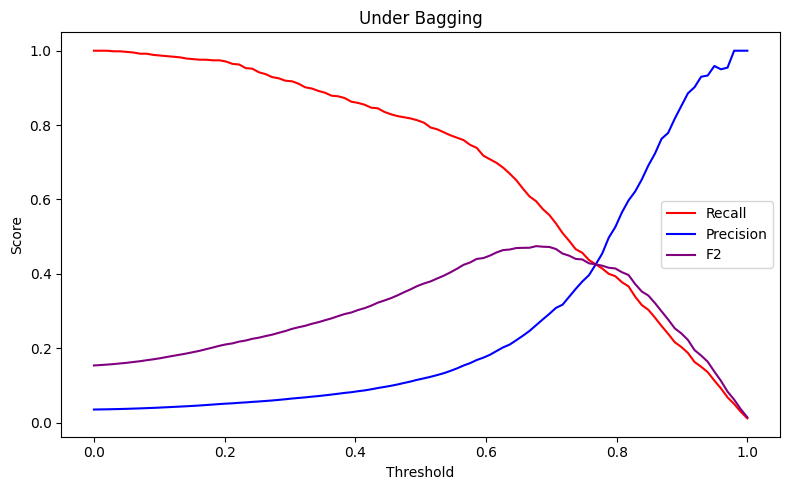
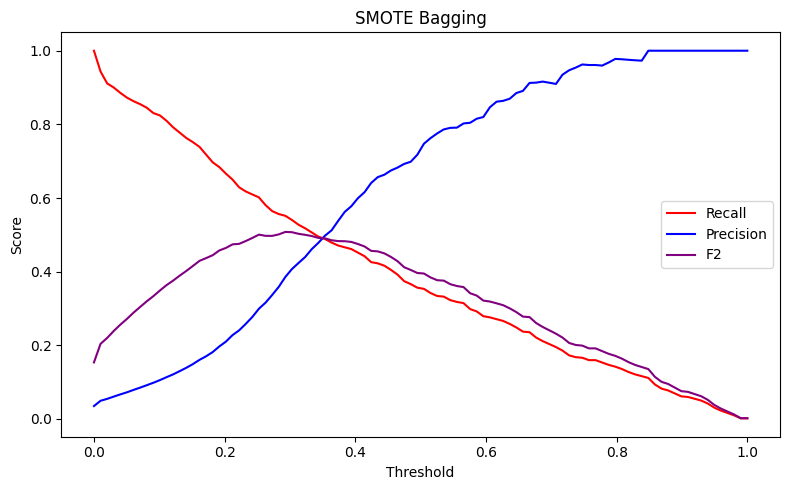
O primeiro gráfico representa um modelo de Random Forest treinado com dados reamostrados utilizando o RandomUnderSampler(). Já o segundo, utiliza uma técnica de amostragem chamada SMOTE, em que são criadas amostras sintéticas das classes positivas, buscando balancear as classes.
Ambas as imagens revelam como o F2-score nos ajuda a encontrar um ponto de equilíbrio que prioriza apropriadamente a detecção de fraudes reais, levando em consideração também a precisão.
Em outros casos, como em sistemas de recomendação de filmes e séries usados pela Netflix, a lógica se inverte. Uma recomendação errada pode irritar o cliente e diminuir sua confiança no serviço. Nesse caso, é melhor não fazer uma recomendação do que fazer uma que o cliente não goste.
Em sistemas de alerta para desastres naturais, o peso dos falsos negativos é enorme - vidas podem estar em risco. Já em autenticação biométrica para acesso a áreas seguras, falsos positivos podem ser mais preocupantes, pois significam acesso indevido.
Em detecção de fraudes, geralmente pendemos para o lado da cautela. Preferimos investigar mais casos suspeitos do que deixar passar uma fraude real. É um preço que escolhemos pagar pela segurança.
Avaliação do Modelo
Com base nas definições do objetivo geral do modelo e sua postura diante de falsos positivos e falsos negativos, o F2-score foi nossa bússola principal na busca pelo modelo ideal.
Também foi usado como complemento a métrica ROC AUC como ponto de referência, considerando a competição do Kaggle. Assim conseguia saber se o modelo era competitivo ou ainda precisava dedicar mais tempo ao pré-processamento e feature engineering.
Para encontrar a melhor alternativa, conduzi diversas experimentações com famílias de modelos distintas, em especial modelos de ensemble, desde LightGBM (boosting) até Random Forests (bagging). Cada modelo foi testado com diferentes técnicas de reamostragem - SMOTE e RandomUnderSampling - para lidar com o desafio das classes desbalanceadas.
Quando me deparava com modelos de performance similar, o F2-score mais alto guiava a escolha - afinal, definimos que a detecção de fraudes reais era a prioridade.
Ao final do processo de experimentação, o modelo que prevaleceu foi uma implementação do método UnderBagging, utilizando o RandomUnderSampler com Random Forest. É uma abordagem que combina performance com eficiência, já que a reamostragem reduz o número de exemplos da classe positiva que são usados para treinar o modelo, tornando o processo de treinamento mais rápido.
Após escolher o modelo, iniciou-se o refinamento das técnicas e dos parâmetros. O primeiro passo, foi realizar simulações com todas as combinações posíveis de rebalanceamento entre as classes e seus pesos relativos.
A reamostragem pode ser total ou parcial. Ao optar por realizar o undersampling total, as classes ficam do mesmo tamanho, mas também é possível escolher qual proporção ideal. A proporção que se mostrou mais efetiva foi de 1:3 - permitindo que a classe minoritária (fraudes) representasse 33% do conjunto de dados de treinamento.
Quanto aos pesos das classes no treinamento, atribuir peso 2 para fraudes e 1 para transações legítimas produziu os melhores resultados. Em termos práticos, isso significa que o modelo "paga o dobro do preço" por não identificar uma fraude real comparado a um falso alarme.
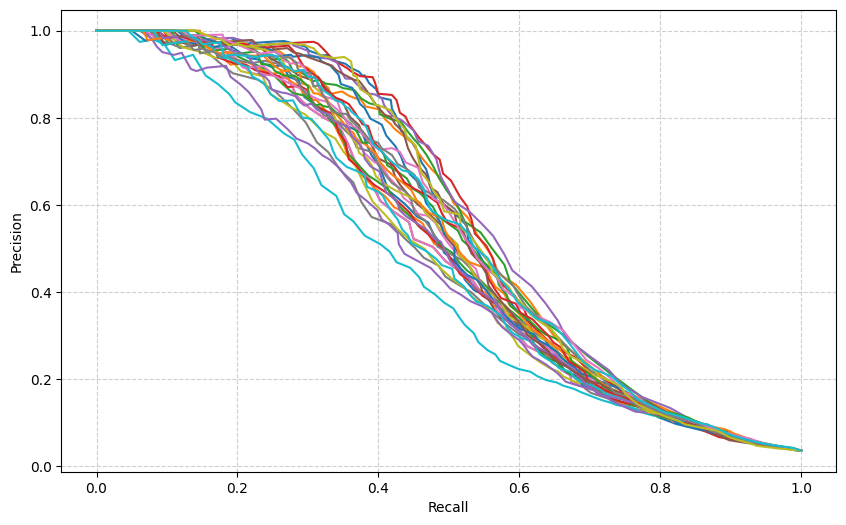
Após as simulações, foi verificado em cada iteração as métricas escolhidas (F2-score e ROC AUC), assim como a curva de Precisão x Recall. No final do processo, foram escolhidas as configurações que apresentaram os melhores resultados.
O último procedimento de ajuste fino foi um processo de otimização de hiperparâmetros usando GridSearchCV(), testando múltiplas combinações para afinar a performance do Random Forest.
Resultado
Após todo o processo de experimentação e refinamento, foi realizado o treinamento do modelo final usando o conjunto completo de dados. A avaliação final do modelo foi feita utilizando um script de treinamento train.py que contém toda a pipeline desde o pré-processamento até criação de features, treinamento, geração de métricas, etc. Vale a pena conferir!
| ROC AUC | Precisão | Recall | F2-score | |
|---|---|---|---|---|
| UnderBagging | 0.91 | 0.31 | 0.70 | 0.56 |
O ROC AUC de 0.9162 é um resultado particularmente bom, tratando-se de problemas de detecção de fraude. Para contextualizar: nesses sistemas, valores acima de 0.9 costumam ser considerados bons resultados, pois indicam que o modelo consegue distinguir bem entre transações legítimas e fraudulentas.
A pontuação obtida nos coloca em um patamar competitivo - para referência, o modelo vencedor da competição do Kaggle alcançou 0.9458, apenas 3 pontos percentuais acima, o que é uma diferença pequena, considerando a complexidade do problema.
A precisão de 0.3149 pode parecer baixa à primeira vista - apenas 31% das transações sinalizadas como suspeitas eram, de fato, fraudes. No entanto, esse resultado reflete o compromisso de maximizar a identificação de fraudes reais, dentro do equilíbrio estabelecido. Em outras palavras, para cada três transações apontadas como possíveis fraudes, duas eram transações legítimas.
Por outro lado, o modelo obteve um recall de 0.7055, o que significa que capturamos mais de 70% de todas as fraudes. Esse número poderia ser ainda maior, próximo de 90%, mas estaríamos sacrificando demais a precisão. O F2-score de 0.5653 reflete esse equilíbrio intencional, dando mais peso ao recall do que à precisão. É um número que representa não apenas performance técnica, mas também alinhamento estratégico com os objetivos do negócio.
Para fins de curiosidade, esse modelo teve um tempo de treinamento de 20 minutos usando uma máquina pessoal relativamente potente. Isso considerando que não usamos a totalidade dos exemplos e apenas 11% da classe majoritária foi mantida para o treinamento, após a reamostragem. Se não tivesse sido aplicada a reamostragem, esse tempo de treinamento seria muito maior.
Conclusão
Busquei apresentar os principais desafios técnicos encontrados no desenvolvimento de um modelo de detecção de fraudes, com foco especial no trade-off entre precisão e recall.
Apesar do atual destaque de modelos de linguagem (LLMs) e IA generativa, modelos de machine learning "tradicionais" continuam sendo amplamente utilizados na indústria para resolver problemas específicos com excelente performance. Empresas como Stone, Nubank e Mercado Livre processam diariamente centenas de milhares de transações utilizando modelos similares ao apresentado aqui.
O aspecto mais crítico no desenvolvimento desses sistemas é a calibragem adequada do modelo para o contexto específico do negócio. No caso de detecção de fraudes, isso significa encontrar o equilíbrio correto entre falsos positivos e falsos negativos, considerando os custos assimétricos de cada tipo de erro e os fluxos estabelecidos para lidar com eles.
Para aqueles interessados em examinar os aspectos técnicos em maior detalhe, o código completo do projeto está disponível no GitHub, incluindo os scripts de treinamento, notebooks de experimentação e documentação detalhada de cada etapa do processo.